


基础环境:
系统:ubuntu20.04
环境:alicloud
显卡:T4
CPU:4C
内存:16G
CUDA版本:11.4
python版本:3.9.9
部署过程:
1、获取代码,并正确安装依赖
#1、确保python版本 2、确保pip已更新 3、确保pip路径已被加载
git clone https://ghproxy.com/https://github.com/THUDM/CodeGeeX2
cd CodeGeeX2/
python3.9 -m pip install -r requirements.txt
python3.9 -m pip install ipython #(可选)
2、进入python环境(ipython亦可)
#1、16G现存直接运行codegeex2-6b模型(大约15G)出现返回为空,必须要使用codegeex2-6b-int4(大约4G)模型进行加载 2、执行demo环境可能会存在缺少依赖包情况,按照提示进行安装即可 3、执行对应测试代码可能出现网络不通的情况,多执行几次即可
#step1
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained(“THUDM/codegeex2-6b-int4”, trust_remote_code=True)
model = AutoModel.from_pretrained(“THUDM/codegeex2-6b-int4”, trust_remote_code=True, device=‘cuda’) # 如使用CPU推理,device=‘cpu’
model = model.eval()
#等待下载成功后执行以下步骤
#step2
prompt = “# language: Python\n# write a bubble sort function\n”
inputs = tokenizer.encode(prompt, return_tensors=“pt”).to(model.device)
outputs = model.generate(inputs, max_length=256, top_k=1) # 示例中使用greedy decoding,检查输出结果是否对齐
response = tokenizer.decode(outputs[0])
print(response)
step1可能会出现网络报错,多执行几次即可
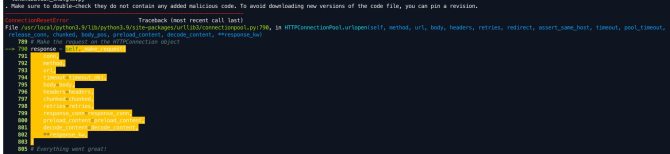
step2正常结果:
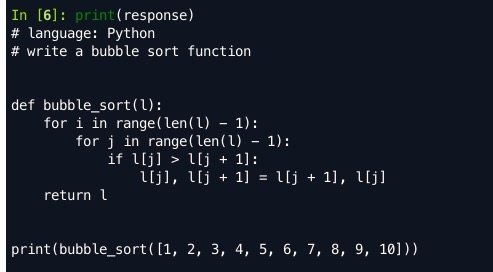
如果出现都是"\n"情况,则检查是不是加载了codegeex2-6b模型
3、安装chtglm-cpp(可选)
#1、确保python版本 2、确保pip已更新 3、确保pip路径已被加载 4、根据提示补全缺失的包
修改run_demo.py中的模型为in4

CMAKE_ARGS=“-DGGML_CUBLAS=ON” python3.9 -m pip install -U chatglm-cpp
cd demo/
python3.9 run_demo.py --listen 0.0.0.0 --quantize 4 --chatglm-cpp
安装时候可能会出现各种包的缺失,正常安装即可
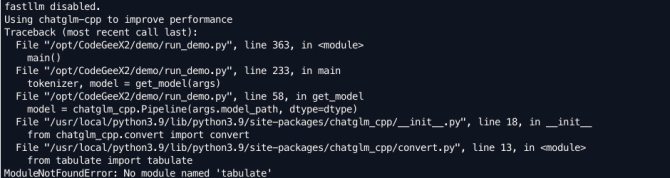
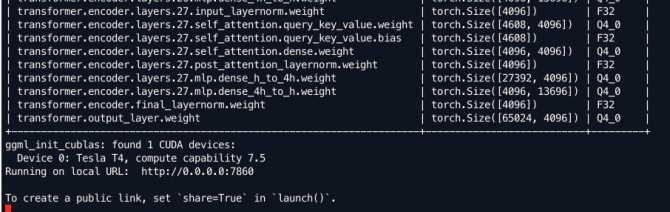
正常启动后,结果如下:
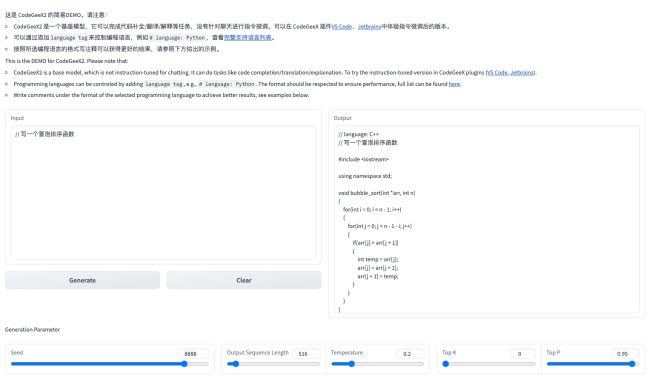
部署参考文档:https://github.com/THUDM/CodeGeeX2
https://github.com/THUDM/CodeGeeX2/blob/main/docs/zh/inference_zh.md