
LightFM模型库简介:
混合矩阵分解模型
通常,大多数推荐模型可以分为两类:
-
基于内容的模型
-
协同过滤模型
基于内容的模型基于项目和/或用户的描述/元数据/配置文件的相似性来推荐。 另一方面,协同过滤模型计算用户和项目的潜在因素基于这样的假设:如果一群人对某个物品表达相似的意见,那么这些人在其他物品上往往会有相似的意见。
两种模型之间的选择主要取决于数据的可用性。 例如,当已经为一组用户和项目记录了足够的评分/反馈时,通常采用协同过滤模型并且该模型有效。
但是,如果缺少评分,则可以使用基于内容的模型,前提是用户和项目的元数据可用。 这也是解决冷启动问题的常用方法,在这种情况下,没有足够的历史协作交互来建模新用户和/或项目。
混合矩阵分解算法
鉴于上述问题,已经提出了许多通过组合基于内容的过滤方法和协作过滤方法来解决冷启动问题的建议。 混合矩阵分解模型是提出的解决方案之一。通常,大多数混合方法提出了与协作信息一起评估和/或组合特征数据的不同方式。LightFM是针对隐式和显式反馈的混合推荐算法的Python实现。
它是一种内容协作混合模型,将用户和项目表示为其内容特征潜在因素的线性组合。 该模型以对用户对项目的偏好进行编码的方式学习用户和项目的嵌入或潜在表示。 这些表示为给定用户的每个项目产生分数。 得分较高的项目更可能使用户感兴趣。为每个功能估计用户和项目的嵌入,然后将这些功能加在一起成为用户和项目的最终表示。
例如,对于用户i,模型检索特征矩阵的第i行以找到权重为非零的特征。 这些特征的嵌入内容随后将被添加在一起,以成为用户表示形式,例如 如果用户10在用户特征矩阵的第5列中具有权重1,在第20列中具有权重3,则用户10的表示形式是第5个特征和第20个特征的嵌入总和乘以其相应的权重。 每个项目的表示都以相同的方法计算。
假设用户特征的第五列值为1,第20列是5,用户的表示向量为sum(第五列权值*1+第20列权值 * 5),如下公式表示,假设用户的特征向量为<math><semantics><mrow><msubsup><mi>e</mi><mrow><mi>f</mi></mrow><mrow><mi>U</mi></mrow></msubsup></mrow><annotation encoding="application/x-tex">e_{f}^{U}</annotation></semantics></math>efU而物品的特征向量为<math><semantics><mrow><msubsup><mi>e</mi><mi>j</mi><mi>I</mi></msubsup></mrow><annotation encoding="application/x-tex">e_j^I</annotation></semantics></math>ejI ,则两者得到的向量分别为加权和:
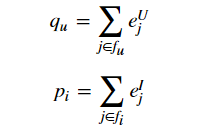
再加上偏置值:
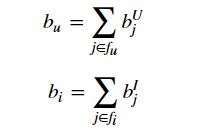
最终的评分计算方法为:
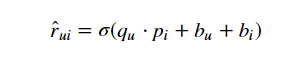
损失函数为,采用负采样的方式进行训练可以有效的降低时空复杂度:
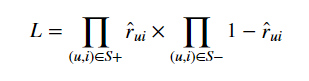
注意:如果特征潜在向量不可用,该算法的行为将类似于逻辑矩阵分解模型。