
目录
- 前言
- 环境准备
- 一、分析网页结构
- 判断网页为静态还是动态
- 二、编写代码
- 请求网址,解析数据
- 循环获取全部数据
- 下载文档图片
- 三、优化代码
- 目的
- 实现过程
- 补充
- 小结
前言
寒假时收到了一个小任务,在百度上下载一些“规范文档”。阴差阳错下,找到了原创力文档这个网站,在里面我找到了所需的全部文档。但是,因为在网站内下载文档需要点小代价,所以我写下了这个爬虫。在此分享一下。(注:仅供学习参考)
环境准备
编程语言:Python3.7 IDE:Pycharm 浏览器:Google Chrome
一、分析网页结构
原创力文档首页网址:https://max.book118.com/  网站首页陈列了部分精选文档,也可通过在搜索框查询所需文档。为方便演示爬虫的效果,我挑选了一篇24页的文档。
网站首页陈列了部分精选文档,也可通过在搜索框查询所需文档。为方便演示爬虫的效果,我挑选了一篇24页的文档。
文档名称:LIMS应用与认可要求 文档网址https://max.book118.com/html/2021/0328/6155232140003130.shtm 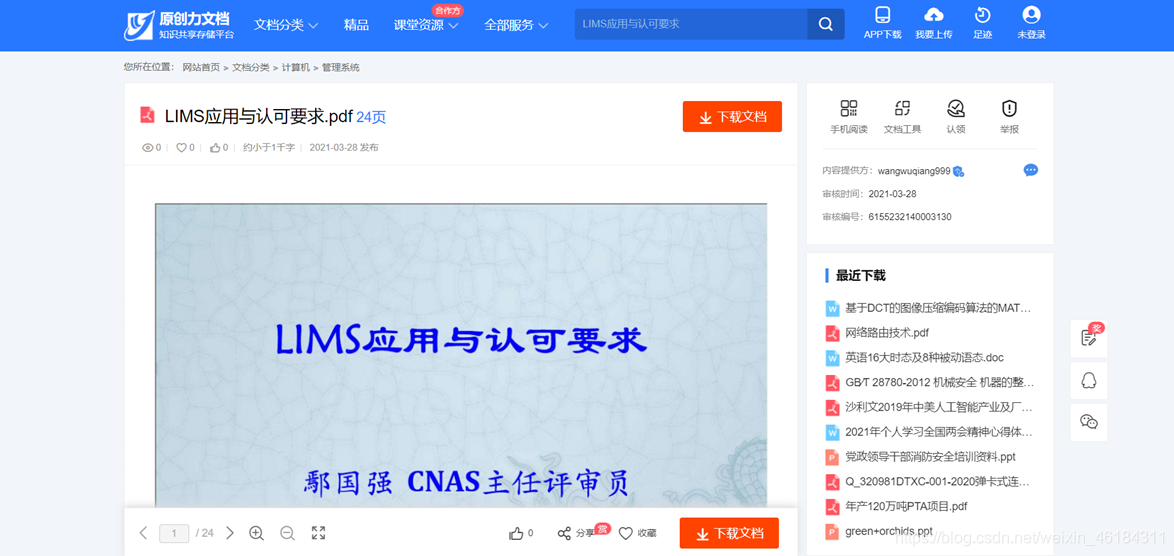
判断网页为静态还是动态
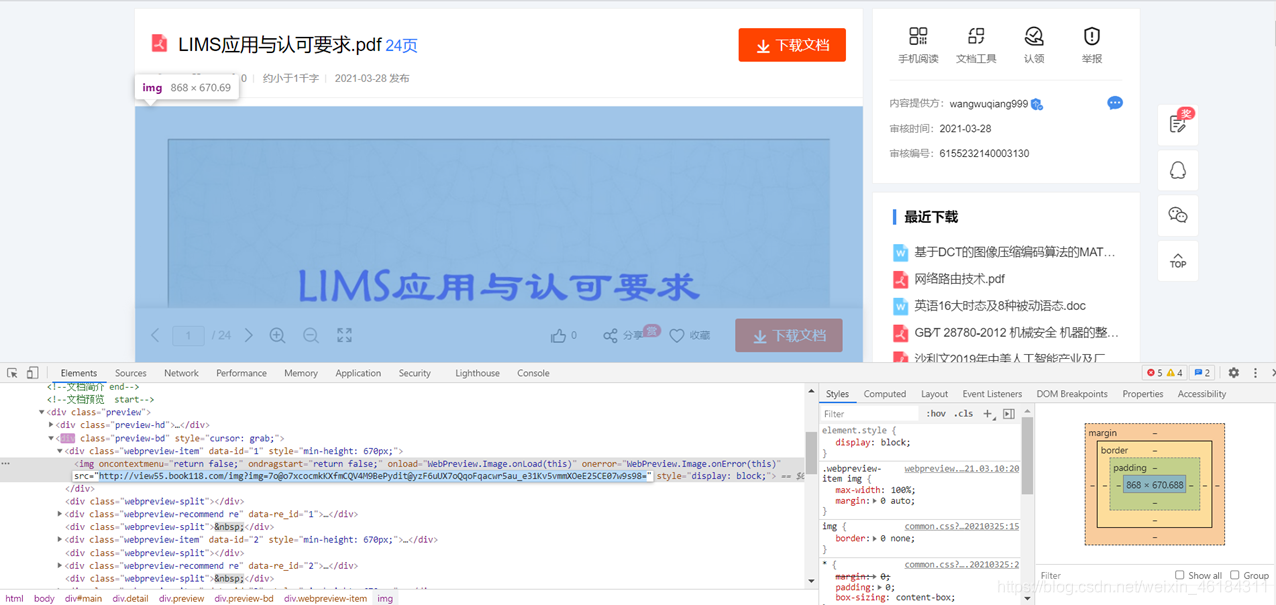 如果该网页为静态网页,通过Google浏览器我们可以很轻松的查找到文档图片的网址,再使用xpath将文档图片悉数爬下。
如果该网页为静态网页,通过Google浏览器我们可以很轻松的查找到文档图片的网址,再使用xpath将文档图片悉数爬下。
然而在查看网页源代时,并没有查询到该网址。 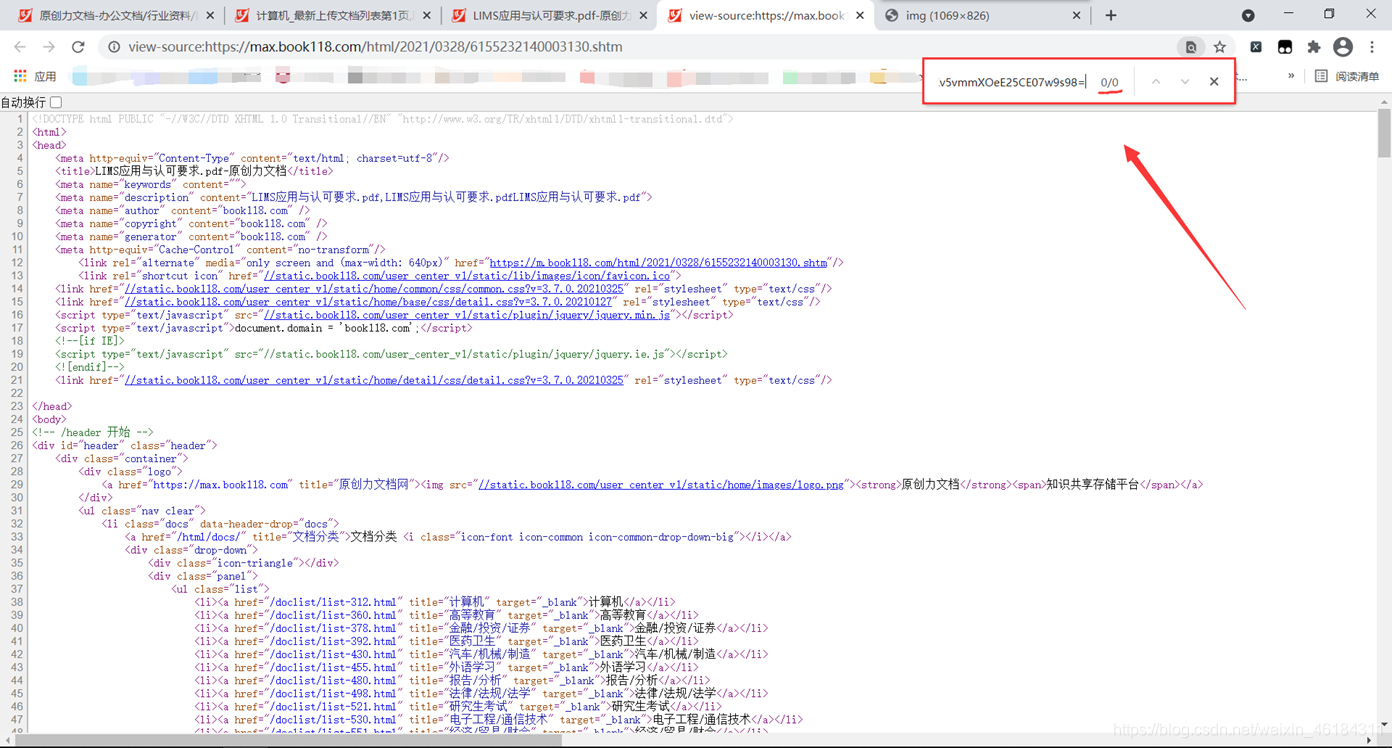 所以很明显,网页为动态网页。
所以很明显,网页为动态网页。
通过浏览器的抓包功能,我在Network中找到一个名为“getPreview.html……”的请求。查看Preview,可以发现里边就是文档前6页图片的网址。 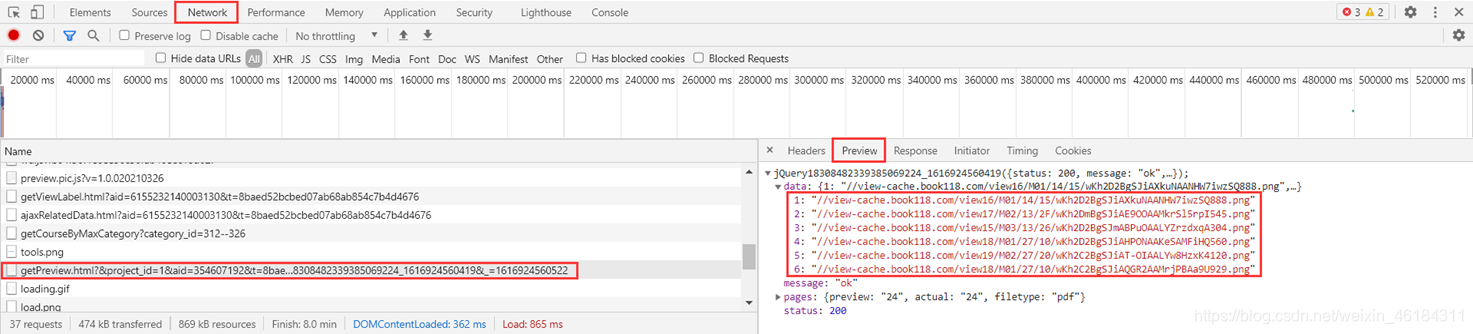 也就是说,此次爬取的目标信息就在Headers中。
也就是说,此次爬取的目标信息就在Headers中。 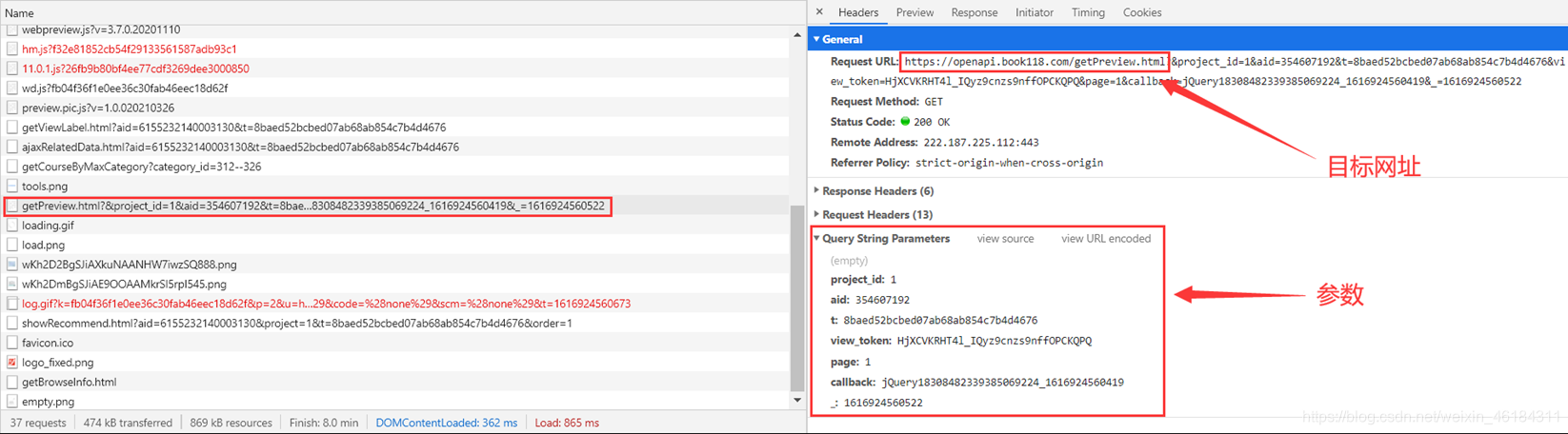
二、编写代码
请求网址,解析数据
代码:
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
url = 'https://openapi.book118.com/getPreview.html'
params = { # 参数(只保留了关键的参数)
'project_id': '1',
'aid': '354607192',
'view_token': 'HjXCVKRHT4l_IQyz9cnzs9nffOPCKQPQ',
'page': '1',
}
response = requests.get(url=url, headers=headers, params=params).text
print(response)
输出结果:  可以发现,返回的是一组json格式的数据,但是因为字符串“jsonpRrturn()”的存在,无法直接使用json.loads()函数对其进行转换。所以我用正则表达式提取了关键数据后,再进行转换。
可以发现,返回的是一组json格式的数据,但是因为字符串“jsonpRrturn()”的存在,无法直接使用json.loads()函数对其进行转换。所以我用正则表达式提取了关键数据后,再进行转换。
转换结果:  转换成json格式数据后,通过key将数据遍历出来,即可获得所需的文档图片网址。
转换成json格式数据后,通过key将数据遍历出来,即可获得所需的文档图片网址。
代码:
response_json = re.search('jsonpReturn\((.*?)\);', response).group(1) # 使用正则表达式所需数据
data = json.loads(response_json)['data']
for i in data.items(): # i[0]为页数,i[1]为网址
img_url = 'https:' + i[1]
print(i[0], img_url)
输出结果: 
循环获取全部数据
目前只获取了文档前6页的内容,而剩下的内容通过修改参数来获取便可。
点击需预览,获取剩下内容的请求。 
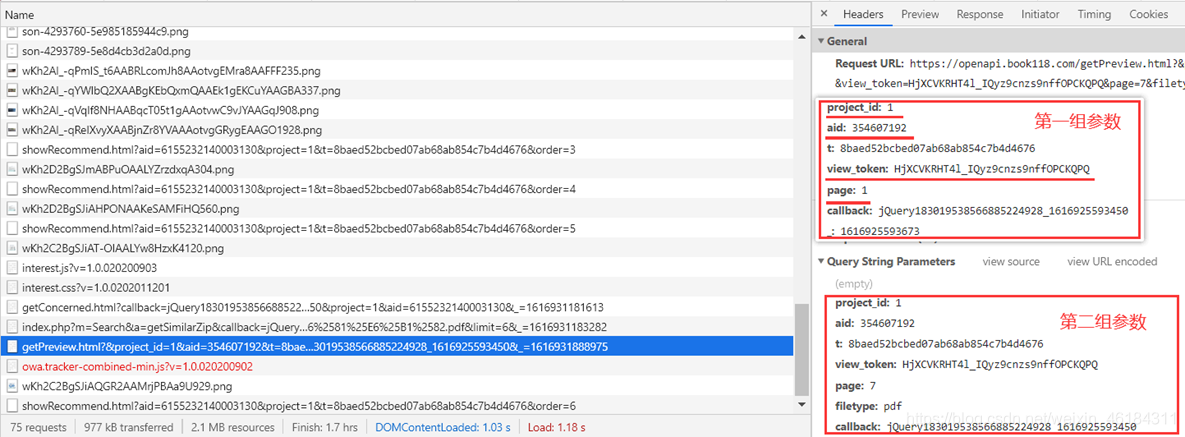 对比两组参数,很容易发现,page发生了变化。
对比两组参数,很容易发现,page发生了变化。
既然1次请求可以获取6页内容,那也就是说24页的内容,4次请求便可以获取全部内容了。并由此推断page的变化情况为1、7、13、19 。使用for循环实现即可。
出现的问题:爬取第六页后的结果全部为空。  为了寻找原因,我单独请求page为7时的内容。发现数据正常的获取到了,推断是请求速度过快,数据还未加载。
为了寻找原因,我单独请求page为7时的内容。发现数据正常的获取到了,推断是请求速度过快,数据还未加载。 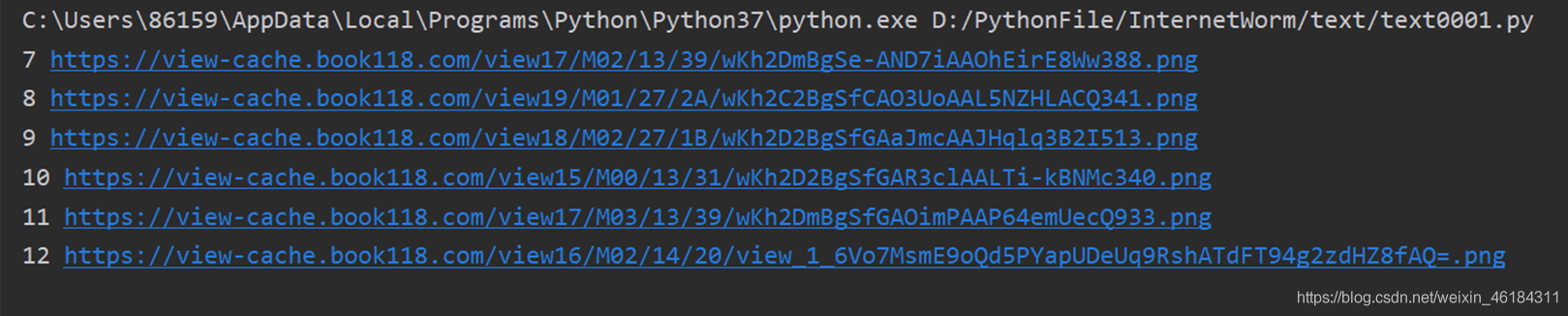 解决方案:使用time.sleep()函数,延迟请求速度。
解决方案:使用time.sleep()函数,延迟请求速度。
代码:
for page in range(1, 20, 6):
params = {
'project_id': '1',
'aid': '354607192',
'view_token': 'HjXCVKRHT4l_IQyz9cnzs9nffOPCKQPQ',
'page': page, # page的变化情况为1、7、13、19
}
response = requests.get(url=url, headers=headers, params=params).text
response_json = re.search('jsonpReturn\((.*?)\);', response).group(1) # 使用正则表达式所需数据
data = json.loads(response_json)['data']
for i in data.items(): # i[0]为页数,i[1]为网址
img_url = 'https:' + i[1]
print(i[0], img_url)
time.sleep(5)
输出结果: 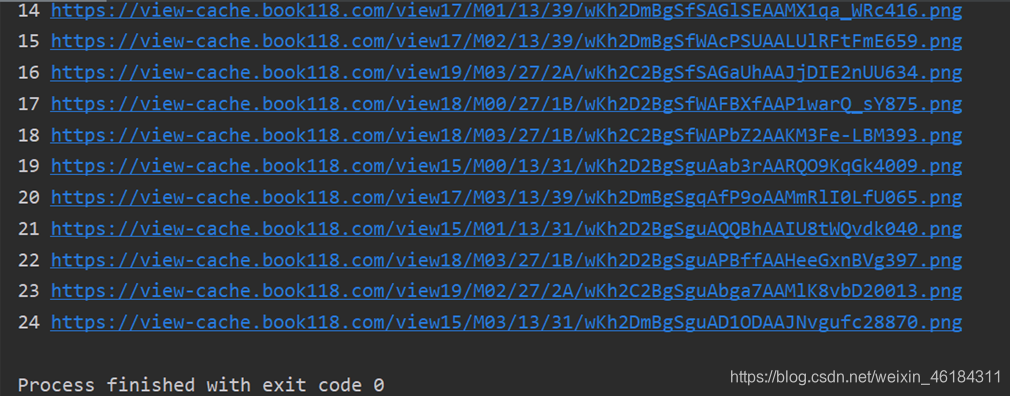
下载文档图片
代码:
urllib.request.urlretrieve(url=img_url, filename=r'D:/yuanChuangLi/{}.png'.format(i[0]))
输出结果: 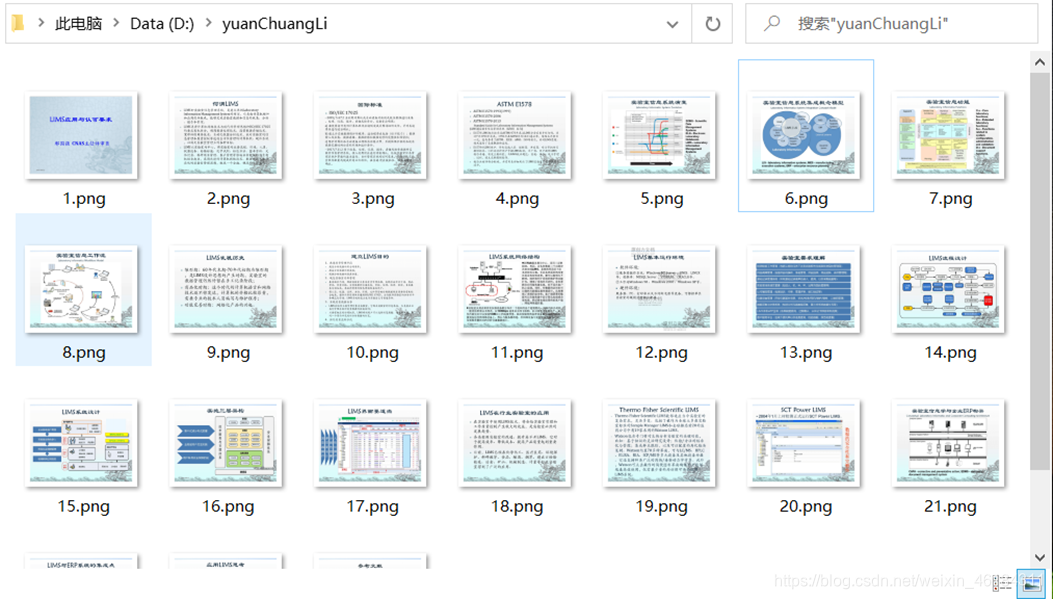 通过一些工具,可将所爬取到的图片转换为PDF格式。这里便不多介绍。
通过一些工具,可将所爬取到的图片转换为PDF格式。这里便不多介绍。
三、优化代码
目的
1)实现输入文档的网址,即可爬取文档内容。 2)增强代码可读性。
实现过程
通过对比不同文档可以发现,不同文档的参数 aid、view_token 会发生改变。那通过修改aid、view_token不就可以获取不同文档内容了吗? 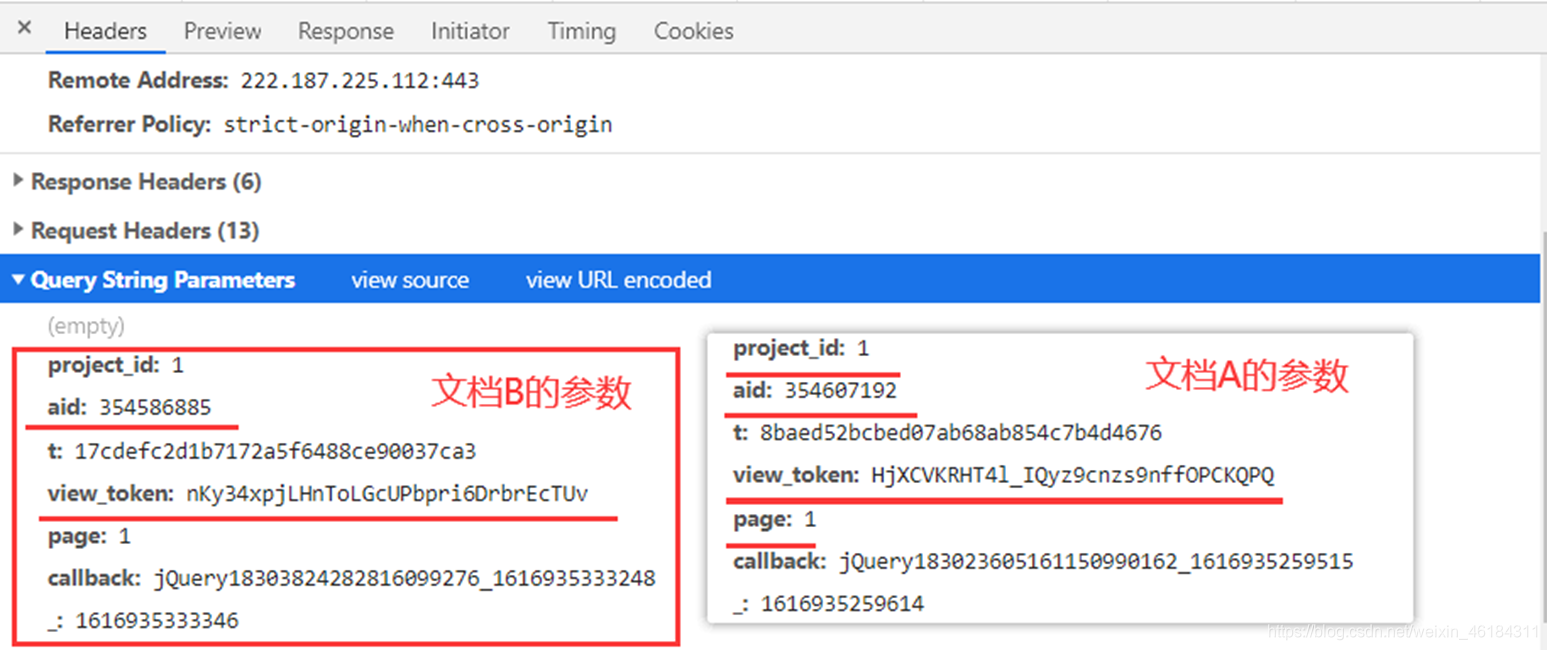 然后我在网页源代码中搜索aid,果然,文档的aid、view_token都在网页源代码里,并且文档的页数也在其中。
然后我在网页源代码中搜索aid,果然,文档的aid、view_token都在网页源代码里,并且文档的页数也在其中。 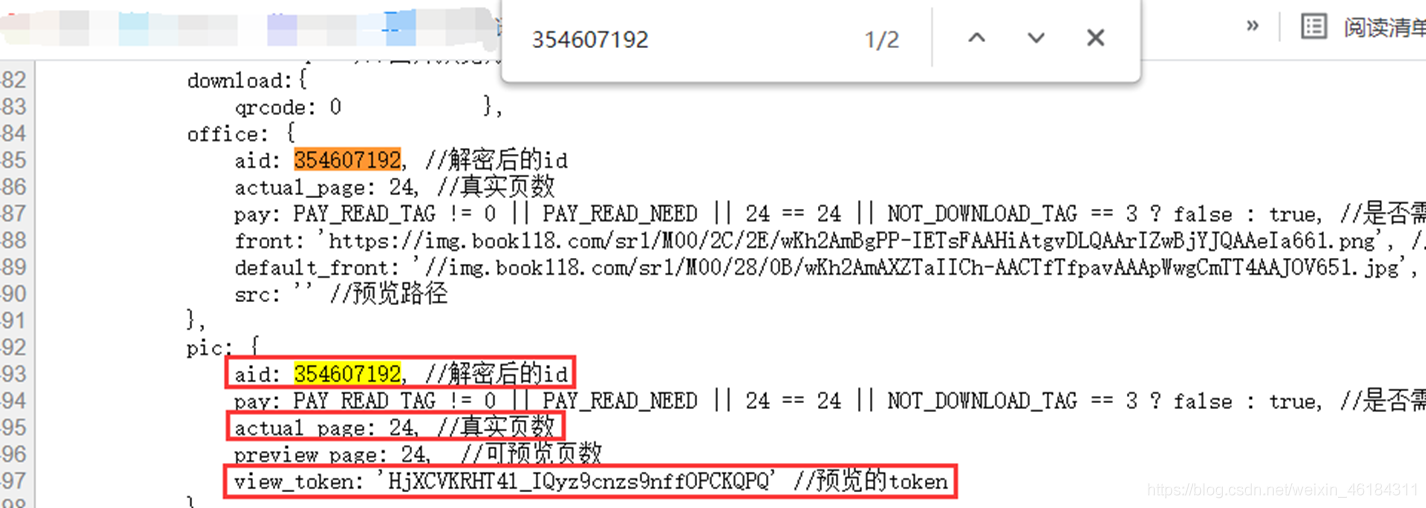 那么,接下来便可以对文档的网址进行请求,再通过正则表达式获取到文档的aid、view_token和页数了。
那么,接下来便可以对文档的网址进行请求,再通过正则表达式获取到文档的aid、view_token和页数了。
代码:
def getParameter():
text_url = input('输入网址:')
text_response = requests.get(url=text_url, headers=headers).text
actual_page = int(re.search('actual_page: (\d+), //真实页数', text_response).group(1))
aid = re.search('aid: (\d+), //解密后的id', text_response).group(1)
view_token = re.search('view_token: \'(.*?)\'', text_response).group(1)
return actual_page, aid, view_token
输出结果:  利用函数调用的方式整理代码,获得最后成果
利用函数调用的方式整理代码,获得最后成果
完整代码:
import requests, json, re, time, urllib.request
def getParameter(url): # 获取文档参数
text_response = requests.get(url=url, headers=headers).text
actual_page = int(re.search('actual_page: (\d+), //真实页数', text_response).group(1)) # 页数
aid = re.search('aid: (\d+), //解密后的id', text_response).group(1) # aid
view_token = re.search('view_token: \'(.*?)\'', text_response).group(1) # view_token
print('actual_page:', actual_page, '\naid:', aid, '\nview_token:', view_token)
return actual_page, aid, view_token
def requests_data(parameter, page): # 请求数据
url = 'https://openapi.book118.com/getPreview.html'
params = {
'project_id': '1',
'aid': parameter[1],
'view_token': parameter[2],
'page': page,
}
response = requests.get(url=url, headers=headers, params=params).text
json_data = re.search('jsonpReturn\((.*?)\);', response).group(1) # 使用正则表达式所需数据
data = json.loads(json_data)['data']
# if data.get(str(page)) == '': # 根据需求使用
# print('数据加载失败,重新发出请求')
# time.sleep(1)
# return requests_data(parameter, page)
# time.sleep(1)
return get_data(data)
def get_data(data): # 下载数据
for i in data.items(): # i[0]为页数,i[1]为网址
img_url = 'https:' + i[1]
# urllib.request.urlretrieve(url=img_url, filename=r'D:/yuanChuangLi/{}.png'.format(i[0])) # 下载图片
print(i[0], img_url)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
text_url = input('输入网址:')
parameter = getParameter(text_url)
for page in range(1, parameter[0], 6):
requests_data(parameter, page)
补充
因为下载图片需要一定的时间,这点时间足够让数据加载出来,这时前面添加的time.sleep()函数就显得鸡肋了。 但是,为了让代码能有更高的容错。我在requests_data模块中添加了以下代码(已在完整代码中):
if data.get(str(page)) == '':
print('数据加载失败,重新发出请求')
time.sleep(1)
return requests_data(parameter, page)
其功能是在请求失败时,利用递归的方式,对请求失败的网址再次发出请求,直到请求成功为止。
输出结果: 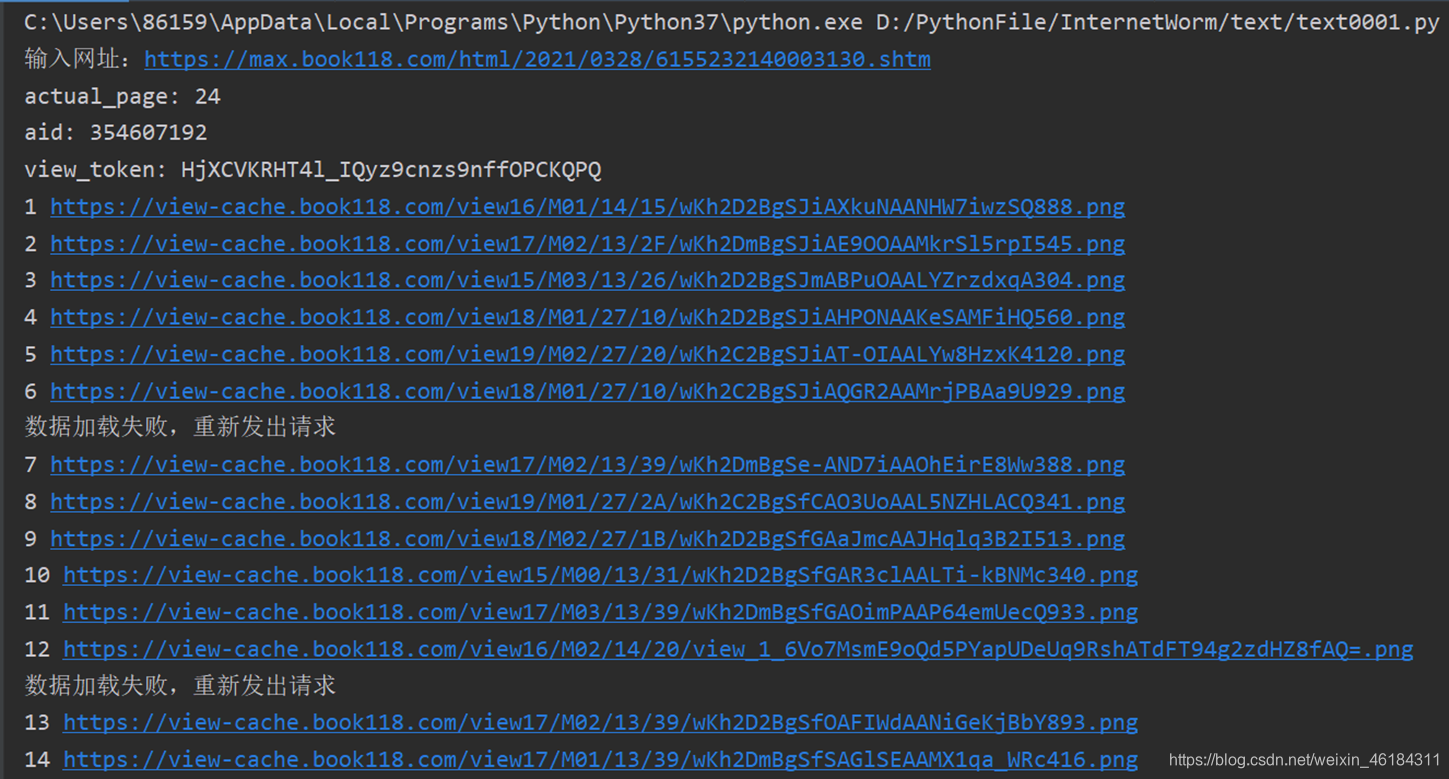
小结
1)经过测试,原创力文档中有小部分为VIP文档,无法爬取。 2)这个爬虫所需技术要求不高,但也算次不错的实操。小伙伴们有兴趣可以练习、扩展一下。
第一次写博客,有很多不足,请多多见谅 谢谢观看。